
Nosql, 4 bases à la loupe 2/4
Vous vous rappelez du bouquin 7 databases in seven weeks ? Pour le coup j'ai eu l'occasion de réaliser une expérience un peu moins ambitieuse, seulement 4 bases de données. Et si je n'ai pas été aussi loin que le bouquin précédent je vous propose quand même un retour d'expérience sur :
- Redis
- Solr
- Elastic Search
- MongoDb
Ce billet fait partie d'une série de plusieurs billets dont le premier est ici. Et le sujet de celui-ci est MongoDb et Redis.
Redis
Note : Redis n'est pas disponible sur Windows du coup j'ai du prendre une version non officielle pour tester.
C'est la première base de données que j'ai testé sous les conseils de Jean Baptiste Lemée. Il s'agit avant tout d'un stockage clé-valeur mais il permet aussi de manipuler des listes et des sets. On hésite parfois à la considérer comme une base de données et plus comme un cache.
Et pourtant c'est bien une base de données, les données sont persisté sur disque.
Sur le chapitre des fonctionnalités Redis, malgré le fait qu'il soit rangé dans la catégorie des bases clé valeurs, reste assez riche. On pourra gérer des transactions, enchaîner des commandes (pipeline), gérer des listes ou des sets. Sur le papier c'est donc pas mal : rapide, fonctionnellement plus riche que d'autres équivalents clé-valeur. Mais malgré tout on est quand même loin de la richesse fonctionnelle attendue, pas de recherche full text ou de géospatial et surtout une représentation des données qui va nous obliger à pas mal de gymnastique.
Avec ce mode de stockage, il faut être imaginatif et changer sa façon de concevoir ces modèles de données. Notamment il faut penser "dénormalisation".
Explication. Redis est orienté clé valeur donc même si nous pouvons stocker notre document sous forme Json il nous sera alors impossible de requêter sur une de ces propriétés, ce n’est donc pas suffisant. Du coup, on va dénormaliser notre objet au maximum et stocker chaque propriété selon des conventions de nommage que nous allons nous fixer. Par exemple pour un objet Profile nous pourrions avoir les records suivants :
"id:1:login" => "loginDuPremierProfile" "login:loginDuPremierProfile" => 1
Ces deux premiers records permettront de rechercher très rapidement o(1) un profile par son login ou bien de connaitre le login du profile d'id 1.
"id:1:email" => "profile@email.com" "email:profile@email.com" => 1
même genre d'exemple avec l'email.
"profile:1:object" => représentation JSON de mon objet Profile
Et enfin un dernier record permettant de stocker l'objet entier lorsqu'on veut le récupérer en une seule fois.
Un exemple avec redis-cli en ligne de commande :
redis 127.0.0.1:6379> get profile:login1:object
"{"address":{"zipCode":"1","loc":[0.0,0.0]},"_id":"login1"}"
Une recherche par login va donc se faire en plusieurs requêtes :
"login:loginDuPremierProfile" va nous renvoyer 1 "profile:1:object" va nous renvoyer l'objet sérialisé en json.
Je ne vais pas plus loin pour mon exemple mais vous pouvez trouver la liste des opérations possibles sur vos données ici : http://redis.io/commands
Voyons les APIs
Jedis
Ce fut a mon sens une erreur en testant Redis, j'ai utilisé Jedis comme client et je suis donc resté très proche du protocole. Sauf qu'il ne s'agit pas du protocole le plus simple.
Voyons par exemple le code pour le cas que j'ai décrit plus haut :
ObjectMapper mapper = new ObjectMapper();
jedis.set("fid:"+profile.getLogin()+":login",profile.getLogin());
jedis.set("flogin:"+profile.getLogin(),profile.getLogin());
jedis.set("fid:"+profile.getLogin()+":zipcode",profile.getAddress().getZipCode());
jedis.set("zipcode:"+profile.getAddress().getZipCode(), profile.getLogin());
jedis.set("profile:"+profile.getLogin()+":object",mapper.writeValueAsString(profile));
jedis.incr("profile:count");
Je sens que vous comprenez à quel point les migrations de données vont être galère (par exemple le jour où vous décidez de rajouter une autre propriété disponible pour la recherche...)
Vous pouvez jeter un oeil sur JedisTest, pour moi ce fut une mauvaise entrée en matière. J’ai peu apprécié l’API. Par contre côté perf je n’ai pas été décu :
JedisTest.findByLoginShouldReturnSomething: [measured 10 out of 15 rounds, threads: 1 (sequential)] round: 0.03 [+- 0.01], round.gc: 0.00 [+- 0.00], GC.calls: 2, GC.time: 0.00, time.total: 57.59, time.warmup: 57.25, time.bench: 0.34 JedisTest.assertThatMyDatabaseHasMoreThan100Profile: [measured 10 out of 15 rounds, threads: 1 (sequential)] round: 0.00 [+- 0.00], round.gc: 0.00 [+- 0.00], GC.calls: 0, GC.time: 0.00, time.total: 0.07, time.warmup: 0.03, time.bench: 0.04 JedisTest.testSearchWithEmbeddedObject: [measured 10 out of 15 rounds, threads: 1 (sequential)] round: 0.03 [+- 0.00], round.gc: 0.00 [+- 0.00], GC.calls: 2, GC.time: 0.00, time.total: 0.43, time.warmup: 0.15, time.bench: 0.28
Et surtout, quelque soit la volumétrie ce temps est constant puisqu'on accède à chaque enregistrement par sa clé.
Par la suite on m'a conseillé d'autres apis sans doute plus adapté :
- Johm
- Spring Data
Johm
https://github.com/xetorthio/johm J’ai voulu tester Johm car le premier a m’avoir aiguillé vers des Apis plus haut niveau m’avait conseillé Ohm (pour Ruby). Mais malgré l’annonce sur Github : JOhm is still in active development., le dernier commit date de 2 ans... J’ai quand même voulu testé mais Johm n’est pas compatible avec les dernières versions de Redis. Epic fail.
Spring data Redis
http://www.springsource.org/spring-data/redis Pour le coup même si j’utilise Spring depuis 2006 et que j’en ai été un grand fan, aujourd’hui je n’avais pas envie de faire entrer le loup dans la bergerie. Je serais ravi d’approfondir le fond de ma pensée autour d’un verre, mais ce n’est pas le sujet de ce billet. Bon, malgré tout si j’avais choisi Redis, ce que je n’ai pas fait au final, je pense que ca aurait été l’API à choisir.
MongoDb
MongoDb fait partie de la famille des bases Nosql orienté document. Plus riche fonctionnellement que Redis on va notamment trouver le support des recherches géospatiales, des fonctions d’aggrégation, le stockage de fichiers de grandes tailles avec GridFS. Par contre pas de transactionnalité excepté au niveau du document, ce qui va nécessiter de recourir à certaines astuces pour gérer la cohérence de nos données. Explication. Tout d’abord s’il n’y a pas de transaction lorsqu’on agit sur plusieurs documents, on a tout de même des "transactions" au niveau document. Ca tombe bien, cette première stratégie consiste donc à stocker des documents Json contenant votre entité et ses relations et c’est exactement ce qui nous convient pour notre relation entre Profile et Adress. Exemple :
{ _id : 1 , login: “login1”, address : { zipCode : “69003”}}
Ici, mon entité inclut un attribut address qui aurait pu être stocké dans une table à part avec un modèle relationnel classique.
D’autres techniques décrite dans la doc permettent d’envisager des “transactions” applicatives : http://docs.mongodb.org/manual/tutorial/perform-two-phase-commits/
Si vous en êtes là, peut être faut-il quand même se poser des questions...
Pour mes tests j’ai souhaité utiliser Jongo et Morphia, deux librairies avec des approches relativement différentes. La première va rechercher la performance en restant très proche du protocole. La seconde va proposer plus de simplicité d’utilisation via un mapping document objet.
Jongo
Jongo reste très proche du shell mongo donc il faut aimer manipuler le json. J’ai été un peu perplexe au début. Je me suis pris quelques murs et puis finalement, avec l’aide de la formation en ligne de 10gen je me suis bien habitué à la syntaxe. Les performances obtenues sont relativement sympa :
JongoTest.findByLoginShouldReturnSomething: [measured 10 out of 15 rounds, threads: 1 (sequential)] round: 0.01 [+- 0.00], round.gc: 0.00 [+- 0.00], GC.calls: 0, GC.time: 0.00, time.total: 0.17, time.warmup: 0.10, time.bench: 0.07 JongoTest.assertThatMyDatabaseHasMoreThan100Profile: [measured 10 out of 15 rounds, threads: 1 (sequential)] round: 0.01 [+- 0.01], round.gc: 0.00 [+- 0.00], GC.calls: 1, GC.time: 0.02, time.total: 0.18, time.warmup: 0.06, time.bench: 0.12 JongoTest.testSearchWithEmbeddedObject: [measured 10 out of 15 rounds, threads: 1 (sequential)] round: 0.03 [+- 0.00], round.gc: 0.00 [+- 0.00], GC.calls: 1, GC.time: 0.01, time.total: 0.52, time.warmup: 0.22, time.bench: 0.29 JongoTest.testGeoSpatialSearch: [measured 10 out of 15 rounds, threads: 1 (sequential)] round: 0.21 [+- 0.03], round.gc: 0.00 [+- 0.00], GC.calls: 3, GC.time: 0.15, time.total: 3.81, time.warmup: 1.67, time.bench: 2.14
Le code complet sous bitbucket
Quelques exemple de code :
return profiles.find("{login:#}",login).as(Profile.class);
return profiles.find("{address.loc : {$near: [0, 0], $maxDistance: 5}}").as(Profile.class);
Morphia
Pour tout dire, nous avions choisi Jongo au début suite aux premières phases de ce bench et à l’époque j’avais obtenu un facteur de 1 à 10 entre Jongo et Morphia. Sauf que maintenant que je maîtrise mieux les deux APIs et les réglages, les dernières tests montrent une autre réalité :
MorphiaTest.findByLoginShouldReturnSomething: [measured 10 out of 15 rounds, threads: 1 (sequential)] round: 0.02 [+- 0.00], round.gc: 0.00 [+- 0.00], GC.calls: 0, GC.time: 0.00, time.total: 0.34, time.warmup: 0.14, time.bench: 0.21 MorphiaTest.assertThatMyDatabaseHasMoreThan100Profile: [measured 10 out of 15 rounds, threads: 1 (sequential)] round: 0.01 [+- 0.00], round.gc: 0.00 [+- 0.00], GC.calls: 0, GC.time: 0.00, time.total: 0.15, time.warmup: 0.06, time.bench: 0.08 MorphiaTest.testSearchWithEmbeddedObject: [measured 10 out of 15 rounds, threads: 1 (sequential)] round: 0.02 [+- 0.00], round.gc: 0.00 [+- 0.00], GC.calls: 0, GC.time: 0.00, time.total: 0.28, time.warmup: 0.11, time.bench: 0.17 MorphiaTest.testGeoSpatialSearch: [measured 10 out of 15 rounds, threads: 1 (sequential)] round: 0.18 [+- 0.04], round.gc: 0.00 [+- 0.00], GC.calls: 2, GC.time: 0.14, time.total: 2.93, time.warmup: 1.15, time.bench: 1.78
Pour le coup, l'API fait vraiment penser à un O(object) D(document) M(Mapping) et on s'éloigne beaucoup plus du protocole.
Quelques exemples :
return ds.find(Profile.class).field("address.zipCode").equal("94500").asList();
return ds.find(Profile.class).field("address.loc").near(0,0,100).asList();
Verdict : Dans les deux cas la mise en place a été très simple. Sur l’aspect performance on reste sur des performances équivalentes. Jongo semble être très souple en restant proche du protocole au détriment par contre d’une lisibilité assez médiocre cependant quand on aborde des requêtes complexes. Avec le recul j’aurais peut être du partir sur du Morphia. Quoi qu’il en soit, utiliser les deux APIs en fonction des besoins ne doit poser aucun souci de toute façon.
Dernier point, en terme de fonctionnalités il me manque encore des capacités de recherche full-text digne de ce nom. Du coup en s’inspirant de ce que beaucoup d’autres ont fait avant nous, nous allons coupler notre solution avec du Lucene.
Mongo et Lucene
Lucene est un superbe outil spécialisé sur la recherche. En terme de fonctionnalités on va retrouver tout ce qui nous intéresse : recherche full text, par synonyme, géospatiale, fuzzy etc...
Tout d’abord, enfonçons des portes ouvertes, on y stocke des documents, on les lit, les supprime, les modifie, oui c’est une forme de bases de données pour ceux qui en douteraient encore.
Du coup, si c’est une base de données et qu’on y trouve toutes les fonctionnalités, pourquoi ne pas en faire notre stockage primaire ?
La première fois que JB m’a parlé d’utiliser Lucene + Mongo ou Redis j’avoue ne pas avoir bien compris le but. Pourquoi deux modes de stockage ? Même après la présentation faite au JUG par Xebia http://www.parisjug.org/xwiki/bin/view/Meeting/20120703 je n’avais pas encore le recul nécessaire. Et oui, il a fallu que je pratique car je fais partie des personnes qui comprennent vite quand on leur explique longtemps ^^
Effectivement ma première idée lorsque j’ai testé Lucene c’était de l’utiliser comme stockage primaire. Sans entrer dans les détails Lucene fait bien la différence entre le stockage d’une donnée, qui permet donc d’utiliser Lucene comme un entrepôt de données, et l’indexation d’une donnée qui la rend disponible pour la recherche. Dans notre cas, il suffisait de stocker la donner en plus de l’indexer.
J’ai donc cherché et lu pas mal d’articles indiquant que la bonne pratique c’était de n’utiliser Lucene que pour rechercher des ID.
Explication.
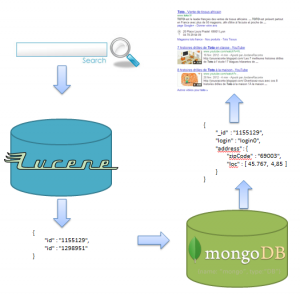
Lucene est optimisé pour les recherches, moins pour manipuler de la donnée et pas forcément la meilleure solution lorsqu’il s’agit de mettre à jour ces données régulièrement. De plus si on stocke chaque information un index lucene peut vite prendre la place. Mongo propose moins de fonctionnalités de recherche mais permet de manipuler des données efficacement.
La pratique courante donc c’est de profiter des capacités de recherche de Lucene et de l’efficacité de Mongo pour le stockage. On stocke uniquement les ID de nos entités sous Lucene et on indexe toutes les propriétés nécessaires à la recherche. Le stockage s’effectue donc sous Mongo. Les recherches permettent de récupérer des ID qui permettront par la suite d’aller chercher nos enregistrements dans Mongo.
Cool, en tout cas une chose était sure, le projet se ferait avec Lucene.
Billet suivant nous verrons que les choses n’étant jamais simples on ne n’est pas contenté de Lucene.
Pour voir chaque billet :
No comments yet. Be the first to comment!