Les bases de l'internationalisation

Mode dépoussiérage activé, aujourd’hui j’ai envie de réactiver une série de billets que je n’avais jamais publié autour de l’internationalisation.
Ces billets ont été écrits en grande partie il y a 8 ans en 2010 lorsque je démarrais localizeyourapps.com un side project qui visait à simplifier le workflow de traduction en l’intégrant au sein de l’usine logicielle. Trève de bavardage, démarrons.
Vous travaillez sur une application et vous souhaitez la rendre disponible partout dans le monde ? Dans ce cas votre logiciel doit s’adapter aux différentes cultures des personnes qui vont l’utiliser à travers le globe.
Cette adaptation va consister à traduire le logiciel, afficher correctement les chiffres, les dates, parfois les images (si elles contiennent du texte par exemple), la mise en page quand la langue s’affiche de droite à gauche ou de gauche à droite et plein d’autre choses encore...
Tout d’abord avant d’aller plus loin, un petit rappel des termes :
- L’internationalisation, que l’on abrège en i18n (car il y a 18 lettres entre i et n dans le mot) consiste à préparer un logiciel pour qu’il puisse être utilisé dans plusieurs pays
- La localisation (ou régionalisation), que l’on abrège en l10n, consiste à localiser le logiciel pour une culture particulière.
L’internationalisation
Comprenons nous bien, lorsqu’on parle d’internationalisation il s’agit d’un ensemble de pratiques et techniques à mettre en place pour être capable de présenter votre site dans d’autres langues et cultures.
Et ça va largement plus loin que de “juste” traduire son site.
C’est quelque chose qui nécessite beaucoup de temps et si vous ne prévoyez pas d’ouvrir votre site à l’étranger tout dans ce billet ne sera pas bon à prendre.
Faut-il anticiper au risque d’en faire trop et de vous ralentir alors que vous n’êtes encore que sur un seul marché ? Ou bien faut-il le faire au dernier moment au risque de devoir tout stopper pendant 6 mois le jour où vous vous y mettez sérieusement ?
De mon point de vue côté ingénierie il y a des pratiques à mettre en oeuvre dès le début du projet car elles font de toute façon partie des bonnes pratiques de base : utilisation de fichiers externes pour les chaînes de caractères, gestion des formatage de date et nombre, encodage en UTF-8 etc…
Mais par la suite, surtout lorsqu’on parlera de localisation, vous verrez que cela va bien plus loin :
- votre partenaire de paiement fonctionne-t-il bien sur les autres marchés et dans une autre devise ?
- l’assurance proposé sur votre site est-elle valable en dehors de France ?
- votre service de support qui fonctionne entre 9h et 18h est-il adapté pour fonctionner avec 6h de décalage horaire.
- vos articles de presse que vous mettez en avant sur votre page “ils parlent de nous” sont-ils vraiment adaptés pour vos clients étrangers ?
- vos CGU sont elles applicables ?
- est-ce qu’il n’existe pas une législation locale qui encadre mon activité et que je dois respecter ? (pensez à la taxe de séjour française pour airbnb par exemple).
etc...
Commençons donc par la partie “simple”, les bonnes pratiques de développement.
Les bonnes pratiques de développement
L’encodage

Les caractères que l’on retrouve dans nos applications sont représentées par un ensemble de code pour la machine. En effet tout doit, in fine, se retrouver réduit à des nombres qui seront transposés en binaire pour un programme informatique.
Pour cela on va associer un nombre à un caractère de façon arbitraire et cette représentation doit ensuite être partagé pour tout le monde pour réafficher et/ou interpréter le texte.
Mettons que je vous dise que la lettre A c’est 1, si je vous envoie 1 vous devez de votre côté le transformer en A.
Et c’est ainsi que sont définis les différents charset (jeu de caractères) qui définissent des associations entre des nombres et des caractères.
Prenons ici un jeu de caractères très simplistes qui permet d’avoir toutes les lettres majuscules :
A -> 1
B -> 2
…
Z -> 26
Avec cette réprésentation simpliste qui ne permet d’écrire que en majuscules , la représentation du mot “FRANCAIS” sera transposé comme suit :
6 18 1 14 3 1 9 19
Par contre il va me falloir compléter ce jeu de caractères si je veux écrire aussi en minuscules, ajouter les accents etc…
Le jeu de code que l’on connaît souvent le plus est l’ISO-latin1 qui nous permet d’encoder chaque caractère français, celui-ci est trop limité et ne permet d’écrire que 256 caractères.
Pour permettre d’écrire en Chinois ou en Japonais par exemple ce sera largement insuffisant et nous aurons recours à un autre jeu de caractères plus étendu, comme l’UTF-8.
Le support d’un jeu de caractères Unicode (qui comprend UTF-8 ou UTF-16) est donc très important pour permettre l’utilisation de votre application dans toutes les langues.
Ce support est natif dans plusieurs langages, Java, C# et Python par exemple.
Par natif j’entends que le programmeur n’a pas d’effort particulière à faire pour écrire et utiliser une chaîne de caractère en unicode sans vous retrouver avec des é ensuite.
En Python 2.x il fallait cependant préfixer les chaînes de caractère par un u :
https://gist.github.com/hlassiege/bc14e4cbbb86f5ca6cf4535ea74c73c0#file-gistfile1-txt
Python 3.x a apporté le support par défaut de l’unicode au langage.
Le support de l’Unicode n’est pas encore natif en PHP (prévu pour PHP6). Mais le module mbstring peut être utilisé pour manipuler des chaines en UTF-8 et les méthodes utf8_decode et utf8_encode permet de faire les conversions nécessaires.
https://gist.github.com/hlassiege/bc14e4cbbb86f5ca6cf4535ea74c73c0#file-gistfile2-txt
(Pour rappel cet article a été écrit en 2010. Depuis, PHP s’est largement vautré sur PHP 6 mais a fini par sortir PHP7 qui supporte désormais nativement l’unicode)
Toutefois le support de l’Unicode par votre langage de programmation n’est pas suffisant, la difficulté principale d’une application c’est qu’elle communique avec d’autres applications.
De façon générale, tous vos flux entrants ou sortants doivent être étudiées afin de vérifier s’ils supportent ou non l’Unicode.
Et surtout, votre application et les autres applications doivent s’entendre sur le jeu de caractères à utiliser.
Et oui, elles savent peut être toutes parler en UTF-8 mais il faut qu’elles se le disent.
La base de données
Considérons que votre base de données est correctement configuré avec le bon jeu de caractères, le code applicatif doit encore s’y connecter correctement.
En Java, l’url jdbc pour Mysql s’écrit de la sorte :
https://gist.github.com/hlassiege/bc14e4cbbb86f5ca6cf4535ea74c73c0#file-jdbcurl-txt
En C#, la connectionStrings pour Mysql :
https://gist.github.com/hlassiege/bc14e4cbbb86f5ca6cf4535ea74c73c0#file-csharputf8url-txt
Pour l’anecdote (*)
Pour SQLServer, la logique est différente, le Charset n’est pas spécifié dans la chaîne de connexion mais est défini au niveau du type des colonnes dans la base. Pour passer en unicode, il faut utiliser les colonnes prefixé par n (nchar, nvarchar, ntext). L’unicode supporté par SQL Server est UTF-16. Attention, avec SQL Server, il faut préciser la collation à utiliser.
(*) qui ne sert à rien mais qui permet de faire comme si on maîtrisait super bien, ce qui relève de l’imposture totale au passage :)
En Python, pour mysql :
https://gist.github.com/hlassiege/bc14e4cbbb86f5ca6cf4535ea74c73c0#file-mysqlpythonconnection.txt
En PHP, pour mysql :
https://gist.github.com/hlassiege/bc14e4cbbb86f5ca6cf4535ea74c73c0#file-mysqlphpconnection.txt
Le charset de vos pages HTML
HTML possède une balise pour préciser au navigateur le jeu de caractères le plus adapté pour restituer votre page. Ici donc, pas de relation avec votre langage de programmation, c’est en HTML que vous spécifiez comment parler Unicode.
https://gist.github.com/hlassiege/bc14e4cbbb86f5ca6cf4535ea74c73c0#file-htmlcharset.txt
Votre application peut aussi renvoyer un header (une information qui sera interprété par votre navigateur) et ce header aura la précédence aura la précédence. Donc vous pouvez aussi envoyer un header HTTP, par exemple en PHP :
https://gist.github.com/hlassiege/bc14e4cbbb86f5ca6cf4535ea74c73c0#file-phpheadercharset.txt
La spécification d’encodage de vos flux XML
De même qu’en HTML, XML définit un attribut pour indiquer l’encodage de vos caractères au différents outils qui vont lire le flux.
https://gist.github.com/hlassiege/bc14e4cbbb86f5ca6cf4535ea74c73c0#file-xmlcharset.txt
Vous l’aurez compris, afin de pouvoir bénéficier du jeu de caractères le plus étendu pour l’ensemble des langues du globe, il vous faudra configurer votre application et celles qui communiquent avec elle en UTF-8.
Maintenant passons à la suite, comment identifier la culture courante.
Identifier la culture courante
Lorsqu’un utilisateur parcourt votre application, vous devez savoir comment il préfère que s’affiche les chiffres, les dates, quelle langue il parle afin de lui proposer le contenu le plus adapté. Il faut donc identifier sa langue et sa culture.
Un mécanisme important pour l’internationalisation d’un logiciel repose donc sur cette identification de la culture de l’utilisateur.
Et j’insiste, plus que la langue, on va parler de culture qui va englober la langue, le pays et les conventions culturelles.
Ca tombe bien, la plupart des langages informatiques proposent un support de cette notion :
- en java, on parle de Locale : http://docs.oracle.com/javase/7/docs/api/java/util/Locale.html
- en .net, on parle de Culture : http://msdn.microsoft.com/fr-fr/library/87k6sx8t%28v=VS.80%29.aspx
- en Python, on parle de Locale : http://docs.python.org/library/locale.html
- en PHP, on parle de Locale : http://php.net/manual/fr/class.locale.php
Dans la suite de l’article on utilisera indifféremment Culture ou Locale.
Pour une application Web
le mécanisme d’identification va se reposer sur un header HTTP : Accept-language. On fera cependant attention à proposer à l’utilisateur un moyen de changer sa Locale car ce header ne suffit pas pour identifier à coup sur la Locale.
Note de 2018 : Ouh la, c’était un chapitre particulièrement trop simpliste ici. Alors oui, on peut se baser dessus mais c’est pas vraiment une bonne pratique. A la limite pour un intranet c’est bon mais si vous avez un site grand public, c’est clairement insuffisant de changer la langue de votre utilisateur uniquement sur la base d’un header et c’est déconseillé d’avoir le même site (les mêmes url) avec des contenus différents selon un header. Côté SEO surtout, les moteurs de recherche souhaitent qu’une url soit toujours associé à une même cible géographique.
Depuis j’ai rédigé un autre article bien plus complet sur l’internationalisation et les noms de domaines.
Pour une application lourde
L’identification de la langue de l’utilisateur repose sur les variables d’environnements du système, par exemple la variable LANG sous Unix.
Sur Windows, la langue se trouve dans la base de registre, dans HKEY_CURRENT_USERControlPanelInternationnalLocaleName.
A noter qu’il existe parfois une méthode unifiée quelque soit l’OS pour récupérer la langue sans avoir à se soucier du nom de la variable et de la façon de la lire en fonction de l’OS.
En Java :
La langue du système peut être récupéré via la propriété système : “user.language” mais un simple appel à Locale.getDefault() va renvoyer la locale du poste.
En C# :
https://gist.github.com/hlassiege/bc14e4cbbb86f5ca6cf4535ea74c73c0#file-getculturecsharp-txt
En Python :
https://gist.github.com/hlassiege/bc14e4cbbb86f5ca6cf4535ea74c73c0#file-getdefaultlocale-py
En PHP :
https://gist.github.com/hlassiege/bc14e4cbbb86f5ca6cf4535ea74c73c0#file-getdefaultlocale-php
Ok, maintenant que vous avez mis en place cette détection de la culture courante, elle va pouvoir vous servir pour la mise en place des fichiers de langues.
Mettre en place des fichiers de langues
Avant de pouvoir localiser, on extrait généralement les chaînes de caractères de l’application dans des fichiers en dehors du code. On sépare ensuite ces fichiers par langues. Un fichier pour le français, un autre pour l’anglais etc... Selon les langages il existe ensuite des mécanismes standardisées afin d’exploiter ces fichiers dans votre application.
Le mécanisme de fallback
Ce mécanisme permet d’organiser les ressources hiérarchiquement et de rechercher une traduction en partant du haut de cette hiérarchie jusqu’au plus bas si on ne la trouve pas.
Dans l’exemple suivant, l’application a déterminé que l’utilisateur parle Français Canadien. Elle recherche donc d’abord la traduction en Français Canadien, puis en Français si elle n’existe pas, puis enfin dans la langue par défaut si la traduction n’a toujours pas été trouvée.
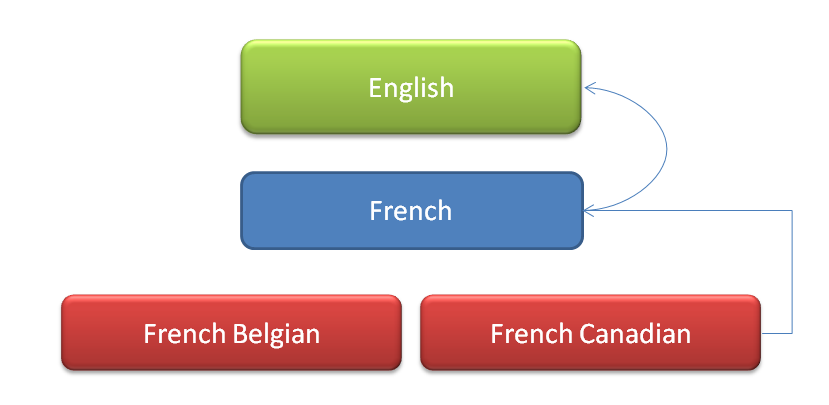
L’utilisation des codes ISO
Une seconde fonctionnalité très commune consiste à utiliser les codes ISO des pays et des langues pour retrouver le fichier de ressources. Ces codes ISO peuvent être utilisés dans le nom du fichier ou le nom du répertoire.
Les codes ISO des langues sont disponibles ici :
http://www.loc.gov/standards/iso639-2/englangn.html
Les codes ISO des pays sont disponibles ici :
http://www.iso.ch/iso/en/prods-services/iso3166ma/02iso-3166-code-lists/list-en1.html
Exemple : fr_FR pour le Français de France constitué de FR, code ISO pour la langue Française et FR code ISO pour le pays France.
Les formats de fichier
Le tableau ci-dessous récapitule les formats et mécanismes implémentés dans différents languages.
| Langage | Format | Mécanisme de fallback | Utilisation des codes ISO |
| Java | ResourceBundle | Oui | Oui |
| .Net | Fichiers Resx | Oui | Oui |
| PHP (*) | ICU depuis la 5.3.0ouTableauouPO (**) | Oui pour ICU et PONon pour les tableaux | Oui pour ICU et PONon pour les tableaux |
| Python | PO (**) | Oui | Oui |
| C++ | PO (**) | Oui | Oui |
(*) PHP ne proposait pas de mécanisme intégré jusqu’à la version 5.3.0. Désormais il supporte le format ICU et un mécanisme de ResourceBundle. L’utilisation du format ICU reste très peu utilisé à l’heure de la rédaction de ce document. Un technique couramment utilisée consiste à inclure des fichiers PHP à partir de la langue choisi par l’utilisateur. Ces fichiers PHP contenant des tableaux de variables avec les traductions de l’application. Cependant il existe aussi une extension pour utiliser gettext (format PO) et c’est pourquoi beaucoup d’applications PHP utilise aussi ce format assez répandu.
(**) Le format PO est celui utilisé par l’outil Gnu gettext. Ce format même lorsqu’il n’est pas supporté nativement par un langage peut souvent être utilisé via une extension.
On peut donc utiliser ce format en Scala, Java, PHP, Ruby, Python, Javascript, C, C++ etc...
Rajout 2018 : En prenant un peu de recul, ce foisonnement de format n’est pas idéal. Tous ne permettent pas d’internationaliser correctement, je pense notamment au support des formes plurielles (que nous verrons plus bas, à la contextualisation etc...). En 2018 les choses n’ont guère évolué. Nous avons toujours Java qui se garde ses multiples trains de retard avec son API (trop) simpliste, d’autres formats qui sont apparus sur mobile, des formats adaptés aux apps Javascript etc…
La mise en oeuvre en dev reste simple cependant :
En Java :
https://gist.github.com/hlassiege/bc14e4cbbb86f5ca6cf4535ea74c73c0#file-getstring-java
En Python :
https://gist.github.com/hlassiege/bc14e4cbbb86f5ca6cf4535ea74c73c0#file-gettext-py
En Php :
Première méthode communément utilisé, on stocke les traductions dans des fichiers, un par langue. Le fichier est inclus de la façon suivante :
https://gist.github.com/hlassiege/bc14e4cbbb86f5ca6cf4535ea74c73c0#file-requireonce-php
ensuite on lit la valeur dans le tableau que l’on sait exister dans ce fichier !
https://gist.github.com/hlassiege/bc14e4cbbb86f5ca6cf4535ea74c73c0#file-readtranslation-php
C’est du bricolage mais cette méthode a été très longtemps utilisé.
Seconde méthode, utilisation de ICU :
https://gist.github.com/hlassiege/bc14e4cbbb86f5ca6cf4535ea74c73c0#file-getstring-php
Je reviendrais plus tard sur ces fameux fichiers et leur intégration dans un workflow de développement.
Le formatage des nombres, des devises et des dates
Les nombres et dates ne s’affichent pas de la même façon dans tous les pays, ça aurait été trop simple.
Si par exemple une date s’affiche Jour/mois/année en France, elle s’affichera Mois/jour/Année aux USA.
Pour un nombre, l’utilisation de virgules ou de points comme séparateur des milliers ou séparateurs de décimales est aussi lié au pays.
Quelques exemples pour les nombres tiré de la doc Oracle :
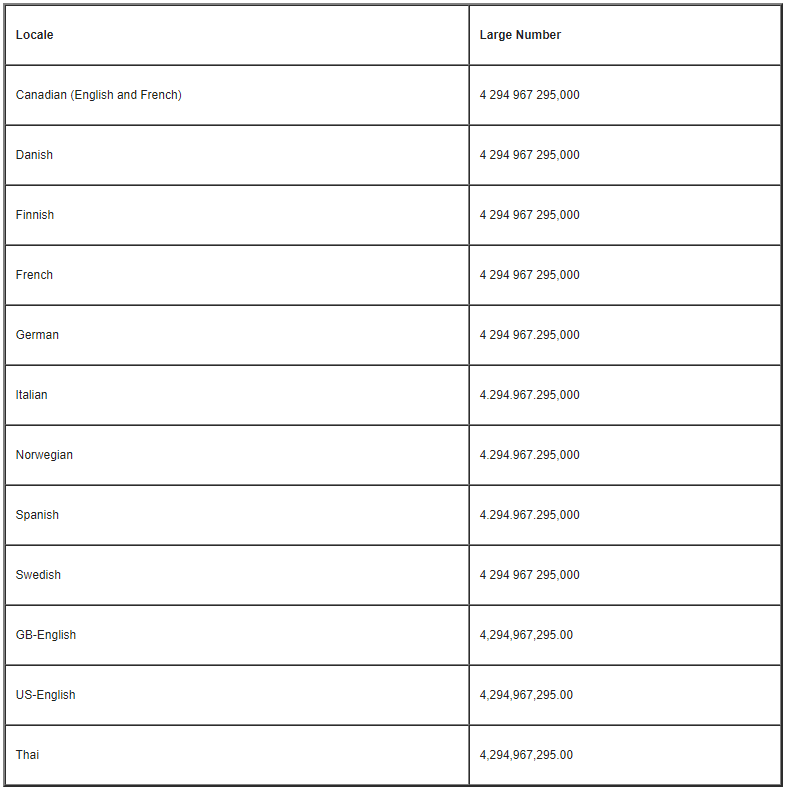
Idem pour l’affichage des montants, on trouvera selon les pays les devises avant ou après le nombre :
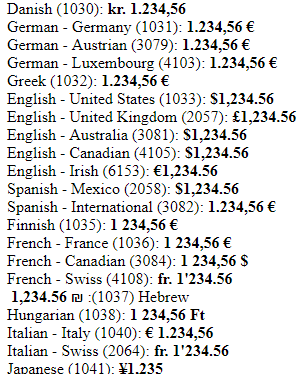
Bref, le foutoir.
Heureusement il existe une méthode standard dans la plupart des langages informatiques qui repose sur la Locale.
Avec la Locale vous laissez le langage choisir comment afficher vos dates, chiffres et montants.
Exemple en Java :
https://gist.github.com/hlassiege/bc14e4cbbb86f5ca6cf4535ea74c73c0#file-numberformat-java
pour une monnaie
https://gist.github.com/hlassiege/bc14e4cbbb86f5ca6cf4535ea74c73c0#file-numberformatcurrency-java
et pour une date :
https://gist.github.com/hlassiege/bc14e4cbbb86f5ca6cf4535ea74c73c0#file-numberformatdate-java
C# :
https://gist.github.com/hlassiege/bc14e4cbbb86f5ca6cf4535ea74c73c0#file-formatcurrency-txt
et pour une date
https://gist.github.com/hlassiege/bc14e4cbbb86f5ca6cf4535ea74c73c0#file-formatdate-txt
En Python :
https://gist.github.com/hlassiege/bc14e4cbbb86f5ca6cf4535ea74c73c0#file-format-py
En PHP :
Malheureusement, la notion de Locale n’est pas supporté correctement par les méthodes de formatage en PHP, il faut donc gérer vous même vos formats ou utiliser une librairie externe (méthode recommandée).
En PHP sans librairies :
https://gist.github.com/hlassiege/bc14e4cbbb86f5ca6cf4535ea74c73c0#file-format-php
On voit rapidement les limitations de ce système pour avoir une application pleinement internationalisé.
Avec PEAR et le module i18nv2 :
https://gist.github.com/hlassiege/bc14e4cbbb86f5ca6cf4535ea74c73c0#file-formatwithpear-php
A noter que Zend propose aussi une API pour l’internationalisation.
Note 2018 : Soyez indulgent, je ne fais plus de PHP depuis 15 ans et je disais sans doute des bêtises en 2010 :)
(j’en dis toujours d’ailleurs)
Alors ok c’est le foutoir mais là, que vous visiez l’international ou non, vous n’avez aucune excuse de ne pas utiliser les fonctionnalités de votre langage, ça ne coûte pas plus cher de bien faire.
La gestion des dates
Bien plus que leur affichage, la gestion des dates est l’un des sujets les plus pénibles quand on parle d’internationalisation. La grande difficulté réside dans le fait qu’une date est relative à un utilisateur, donc tout traitement qui les manipule, fait des différences de date ou calcule des anniversaires doit prendre en compte la zone temporelle. A cela vous ajoutez les soucis d’heure d’hiver/été qui ne sont pas identiques partout, les pays qui couvrent plusieurs timezone (et ceux qui ont décidé d’avoir la même heure malgré cela), les secondes intercalaires, les années bisextiles. Envoyer un email pour l’anniversaire d’un utilisateur peut déjà être un sport, calculer le temps d’une de ces communications si vous êtes un acteur téléphonique et que l’utilisateur est en roaming est aussi bien sympathique.
Bref, je ne vais pas entrer dans le détail mais le conseil relativement très général c’est surtout d’éviter de ne manipuler une date ou un timestamp sans information de timezone. Et encore plus en base de données, bien stocker la timezone est primordiale et pas juste se baser sur la timezone du serveur qui fait tourner votre base de données (qui peut changer éventuellement ou être mal réglé).
Les images
Les images ont parfois besoin d’être internationalisé car elles contiennent du texte ou ont des références culturelles qu’il faut pouvoir adapter à un autre pays.

Malheureusement l’internationalisation d’une image est moins standardisée. Seul C# propose un mécanisme à travers les fichiers resx qui peuvent aussi contenir des images.
Astuce : On peut cependant utiliser les fichiers de ressources pour stocker les noms des images et ainsi réutiliser le mécanisme standard de localisation pour les images. Par contre ne mélangez pas ces chaînes “techniques” à vos traductions sinon bon courage pour expliquer à vos traducteurs ce qu’il faut faire de ces chaînes de caractère.
Bonne pratique :
Le coût de localisation d’une image étant souvent supérieure à la localisation d’un texte, il est préférable dans la mesure du possible d’éviter l’utilisation d’image avec texte. Il est possible d’ajouter ce texte à la volée via un post traitement de l’image et de mettre en cache les images localisées pour des questions de performance ou parfois d’appliquer le texte en CSS dans le cadre d’une application Web.
la taille des textes à l’écran
La taille des textes varie en fonction des écritures. Si le design de votre application est au pixel près, le changement de langues peut avoir des effets dévastateurs.
La longueur du texte varie horizontalement : en effet si “anticonstitutionnellement” fait 25 caractères en français, il n’en fera que 17 dans sa traduction allemande (*). Sur un formulaire avec le label placé à gauche du champ de saisie l’alignement peut être cassé par un texte trop grand dans une des localisations.
Parmi les solutions que l’on peut mettre en place :
- Placer les labels au dessus des champs de saisie
- Prévoir plus de place pour les labels
(*) Et c’est un peu l’exception, de façon générale un texte en allemand prendra plus de place
La longueur du texte varie verticalement : certaines langues, comme le Japonais ou le Chinois, vont nécessiter une plus grande taille de police pour être lisible.
Parmi les solutions :
- Choisir dès le début une police plus grande pour tous les langages
- Laisser la possibilité à l’utilisateur de choisir d'agrandir sa police
Pour une page web, une bonne pratique consiste à utiliser l’unité em pour le conteneur principal et en % pour les conteneurs en dessous laissant ainsi à l’utilisateur la possibilité de choisir lui-même la taille par son navigateur
Pour une application en client lourd, une option doit permettre de choisir la taille de police.
Exemple :
Ici, splitweet (note 2018 : site qui n’existe plus aujourd’hui) propose une mise en page centrée avec taille fixe en largeur. La police initiale est déjà assez grande et ne change pas en passant au Japonais par contre le div du dessous s'agrandit sans casser le reste de la mise en page.
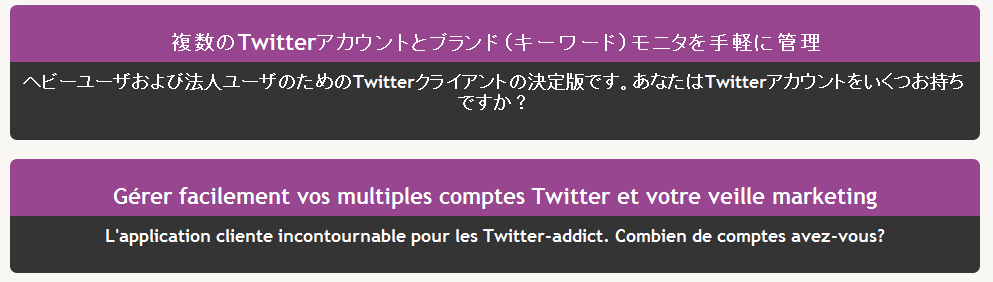
Même choix chez Atlassian, la police initiale est assez grande pour ne pas avoir besoin de la changer. La mise en page n’est pas cassée malgré le fait que les paragraphes sont plus petits sur la version Japonaise.


l’affichage LTR (left to right) et RTL (right to left)
Si vous visez un public multilingue très large, alors il vous faut aussi gérer la directivité du langage.
C’est sans doute l’un des aspects de l’internationalisation le plus complexe et beaucoup de sites font l’impasse dessus (par exemple Twitter ou Jira ne proposent pas de langues RTL)
Il existe deux formes d’écriture généralement supporté, l’écriture de droite à gauche et celle de gauche à droite. S’il existe aussi des écritures à directivité verticale, celles-ci acceptent d’être retranscrites en LTR ce qui fait que le support de l’écriture verticale n’est pas nécessaire.
Pour une application web
Il existe un attribut pour préciser la directivité d’un élément. Ainsi
https://gist.github.com/hlassiege/bc14e4cbbb86f5ca6cf4535ea74c73c0#file-htmldirection-html
S’affichera :
שלם
et
שלם
Et il existe aussi une propriété css : direction.
Mais il ne suffit pas de changer l’alignement des textes, c’est aussi le positionnement des éléments qui est à revoir pour des questions de convention.
L’utilisation de feuilles de style redéfinissant les alignements et positionnement est donc nécessaire mais cela nécessite un énorme travail lors du design de l’application pour supporter deux mises en pages radicalement différentes.
Exemple :
Facebook gère bien le passage à l’Arabe. Tous les positionnements sont inversés, y compris la barre d’action.
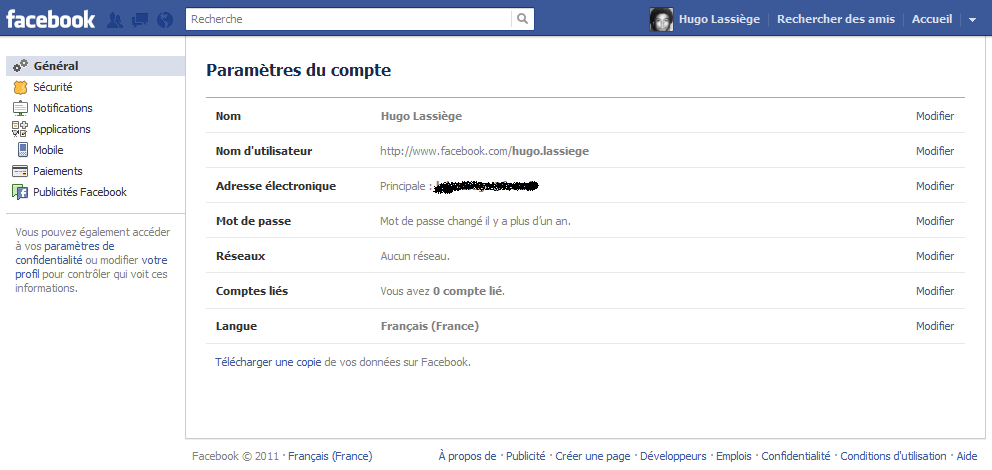
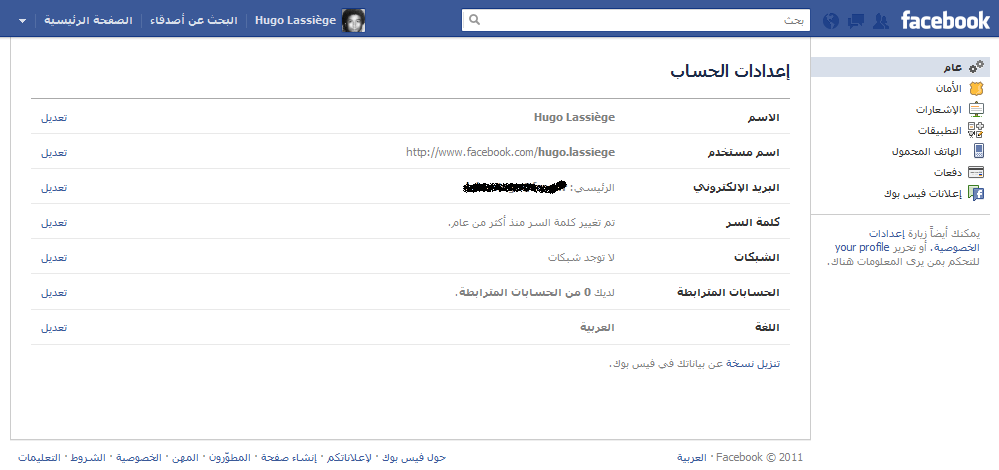
Pour aller plus loin
L’idée n’était pas d’être exhaustive mais vous avez déjà un bon aperçu des problématiques classiques d’internationalisation. Et quand je dis que ce n’est pas exhaustif, je vous laisse méditer sur ces autres sujets :
- le système de mesure : qui peut être métrique ou impérial
- le format d’impression : a4, lettre US etc...
- le système de mesure pour les chaussures et vêtements
- le référencement d’un site web
