Intégration avec Hull et considérations pratiques sur l'usage d'APIs

Je vous propose aujourd'hui de découvrir Hull. que nous utilisons depuis quelques mois chez Malt.
Hull fait partie des outils de "Data Marketing" (marketing dirigé par la donnée). C'est un outil qui permet d'unifier des données de plusieurs sources (analytics, crm) et/ou de les dispatcher vers plusieurs sources (mailchimp, intercom) tout en gardant la main sur la donnée, sa segmentation (audiences), son cycle de vie.
Comme je le disais plus haut, l'outil permet donc, par exemple, de créer des audiences à un seul endroit et de les pousser dans les outils d'envoi d'email, sms etc… pour ne pas reparamétrer cela dans chaque outil. C'est aussi une sorte de Hub de consolidation de données qui enrichit l'information dans plusieurs outils et la redispatch.
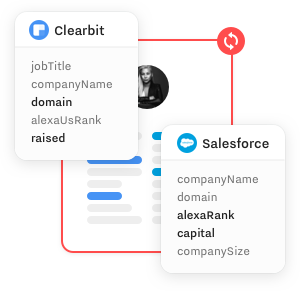
image tiré de leur site qui illustre l'enrichissement par plusieurs sources
Je ne vais pas trop m'étendre sur le fonctionnel, ici je vous propose plutôt de parler des problématiques d'intégration.
C'est un billet un peu "niche" qui intéressera moins de monde mais je trouve les problématiques assez intéressantes en terme d'API et je me trouve moi même assez souvent en manque de sources quand je cherche à utiliser ce type d'outils. Même si vous ne connaissez pas ou ne comptez pas utiliser Hull, les réflexions sur l'ingestion et l'export de données vous intéresseront peut-être.
Disclaimer
Vous allez me dire que certains produits n'ont pas besoin qu'on leur dédie des billets de blog parce que leur doc est très bonne. Et c'est pas faux. Hull a une documentation en ligne mais c'est un produit jeune et la documentation n'est pas toujours exacte ou exhaustive. Cependant elle s'améliore.
Maintenant que les présentations sont faites, parlons de la première étape : l'injection de données.
Pour injecter de la donnée nous avons plusieurs possibilités :
- l'API Firehose
- un Webhook
- Un connecteur SQL
Utilisation de l'API Firehose
L'api est documenté ici : https://www.hull.io/docs/data_lifecycle/ingest/#firehose-api
Au moment où j'écris cette documentation elle a légèrement changé depuis le moment de notre intégration.
Notamment cette api devait auparavant nécessiter que l'on créé un connecteur de type incoming Webhook pour l'utiliser. Désormais on peut l'utiliser sur une url globale firehose.hullapp.io, même s'il faut toujours créer un connecteur pour avoir des credentials.
Ce n'est pas notre cas, nous sommes restés sur l'ancienne url et il est possible que cela explique de très nombreuses erreurs 500, 502, 504 que nous avons.
Justement, faisons une digression sur le sujet.
Comment gérer la fiabilité (ou absence de fiabilité) d'une API externe
Que ce soit Hull ou n'importe quel autre fournisseur, il faut partir du principe qu'une API externe n'est pas fiable. Cela peut être lié au réseau, ou à l'API elle même.
Sans parler de fiabilité, certaines API imposent un certain Rate Limiting (nombre d'appels max par période de temps).
A ce propos Hull n'impose pas de Rate limiting et gère au contraire celui des API externes au niveau de ces connecteurs. Très bon point.
Comme cela fait plusieurs fois que je parle de connecteur, je me permet d'en donner une définition très simple : un connecteur permet de déverser des données vers une destination ou d'aspirer des données depuis une source. Cela vous rappellera peut être des tas d'outils qui utilisent ces notions d'input/output, comme Logstash par exemple. Sauf que les connecteurs Hull sont souvent fait pour aspirer/envoyer des données vers des produits/SAAS et non juste des composants techniques (bases de données).
Reprenons, même en évacuant cette notion de Rate limit, il reste la notion de fiabilité d'une API.
Au tout début de notre intégration, nous avions le pattern suivant
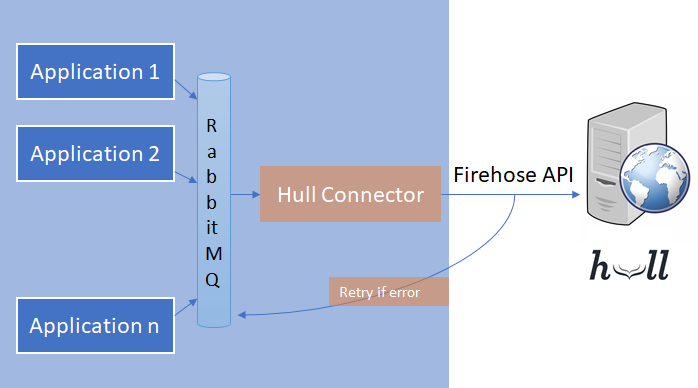
Pour résumer :
- lecture d'un event symbolisant un ordre de mise à jour de Hull
- appel de l'API Firehose
- En cas d'erreur, le message était réempilé en queue et relu plus tard
Très bien, c'est résistant à l'erreur en théorie.
Mais cela peut avoir plusieurs défauts :
- on logge malgré tout des erreurs à chaque retry. Si l'API est capricieuse (c'est le cas de celle de Hull), c'est beaucoup de logs d'erreur "attendus"
- on induit une pression en plus sur une API déjà un peu malade, au risque de ne jamais lui permettre de s'en remettre.
Nous avons fait une première action en changeant les choses comme cela :
- lecture d'un event
- appel de l'API
- en cas d'erreur, retry silencieux avec un délai
- log d'erreur uniquement au bout de 10 tentatives
C'est mieux mais dans certains cas, ça nous laissait malgré tout de nombreux messages en deadletter queue sur RabbitMQ et cela, sans limite de temps.
Après 10 tentatives on reste dans la situation où l'on loggue beaucoup d'erreurs.
(et donc on casse nos quotas de logs sur Sentry, snif…)
De plus la deadletter de Rabbit n'est pas requêtable. On ne peut pas non plus filtrer les messages par queue d'origine etc… Donc cela reste assez pauvre si on veut contrôler ce qu'il y a dedans.
Dans le cadre de ce projet nous avons développé une nouvelle solution avec une mise en quarantaine des messages dans une base de données :
- lecture d'un event
- appel de l'API
- en cas d'erreur, retry silencieux avec un délai
- log d'erreur uniquement au bout de 10 tentatives
- mise en quarantaine au bout de 11 tentatives .
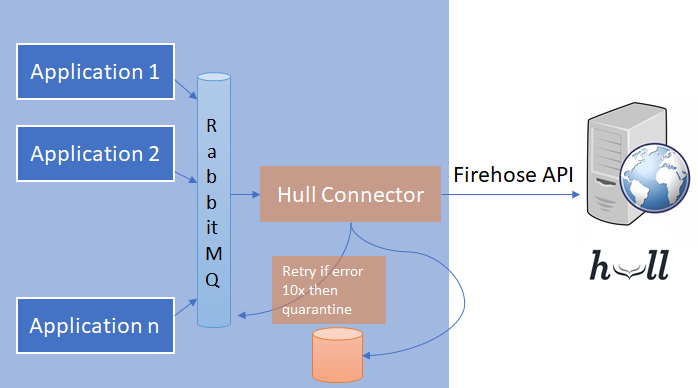
Il y a clairement du mieux, depuis cette quarantaine on peut filtrer les messages par queue d'origine, voir les messages en questions, rejouer les events selon un filtre etc…
Malgré tout, nous avions un autre point.
En effet je parlais d'event tout à l'heure. Un event est de la forme : ProfileUpdated, AccountUpdated, EmailUpdated, ConversationStarted etc… Il existe de très nombreux events et on veut mettre à jour Hull sur beaucoup d'event car cela peut changer des informations ou des statistiques importantes (taux de contact par exemple).
Une action peut entrainer plusieurs events de nature différente.
Autrement dit, pour un même user, il est possible d'appeler Hull plusieurs fois avec des données très proches dans des laps de temps assez courts.
Il se trouve que Nicolas, Lead developper chez Malt, travaillait lui aussi sur une API partenaire à ce moment là : Oracle Netsuite. Si Hull est parfois capricieux, ça reste une API qui fonctionne. Netsuite en comparaison est une horreur à plus d'un titre.
Et comme cette notion d'appel à des API partenaires est un sujet qui revient souvent il a développé une queue de commande qui permet entre autre :
- de prendre en compte les rates limites des API (inutile pour mon cas)
- de dédoublonner les appels
- de garder des séquences de commandes à faire dans un ordre
- de gérer les retry
C'est pas le sujet de l'article donc Nico développera sans doute dans un autre billet à part car c'est devenue une brique très pratique chez nous.
Je l'ai réutilisé sur Hull et j'ai donc désormais également un outil qui permet de temporiser mes envois sur Hull et qui dédoublonne par tranche de temps (configurable) pour éviter d'envoyer trop de commandes à Hull.
Gestion de tokens JWT
Je ne vais pas revenir sur l'usage de l'API Firehose elle-même qui est pas trop mal documentée.
J'ai cependant rencontré des difficultés sur les tokens JWT qui doivent être inclus dans ces appels.
Un appel Firehose doit contenir plusieurs blocs d'informations. Chaque bloc d'information contient un header et ce header contient un token JWT.
Au moment de l'intégration, la doc qui décrivait ce token était relativement petite. On peut la retrouver ici, elle s'est améliorée.
Ce qu'elle ne décrit pas bien, c'est la structure d'un token d'exemple. Je vous propose donc de regarder à quoi cela ressemble :
Hull-Access-Token : { "io.hull.active" : true, "io.hull.create" : true, "io.hull.asUser" : {"external\_id" : "maltUserID"}, "io.hull.subjectType" : "user", "io.hull.asAccount" : {"external\_id" : "maltCompanyID"}}
io.hull.asUser permet de définir l'identité à utiliser pour résoudre l'utilisateur chez Hull. Il permet notamment d'utiliser un external_id qui peut être par exemple l'id dans notre système.
On peut aussi faire la liaison entre un user et sa société, concept existant chez nous, en ajoutant un attribut io.hull.asAccount et qui définit l'ID de la société.
L'objet déclaré plus haut est facile à construire à partir d'une Map.
Par exemple
Map mapOfClaims = new HashMap<>(Map.of(
"io.hull.active", true,
"io.hull.create", true,
...
));
Ensuite il faut signer cet objet avec JWT. En Java cela donne :
public static String sign(String secret, String issuer, Map mapOfClaims) throws JoseException {
JsonWebSignature jwtSigner = new JsonWebSignature();
jwtSigner.setKey(new AesKey(secret.getBytes()));
jwtSigner.setAlgorithmHeaderValue(AlgorithmIdentifiers.HMAC\_SHA256);
JwtClaims claims = new JwtClaims();
claims.setIssuer(issuer);
claims.setIssuedAtToNow();
claims.setExpirationTimeMinutesInTheFuture(20);
mapOfClaims.forEach(claims::setClaim);
jwtSigner.setPayload(claims.toJson());
return jwtSigner.getCompactSerialization();
}
Petit point d'attention sur le claims.toJson() qui utilise donc une serialisation JSON de votre Map.
Et donc pour les sous objets io.hull.asUser et io.hull.asAccount il faut bien penser à utiliser un JSONObject, sinon la sérialisation va donner
"io.hull.asUser" : "{\"external_id\" : \"maltUserID\"}" et non pas "io.hull.asUser" : {"external_id" : "maltUserID"}
Oui c'est bête mais j'ai fait l'erreur au début…
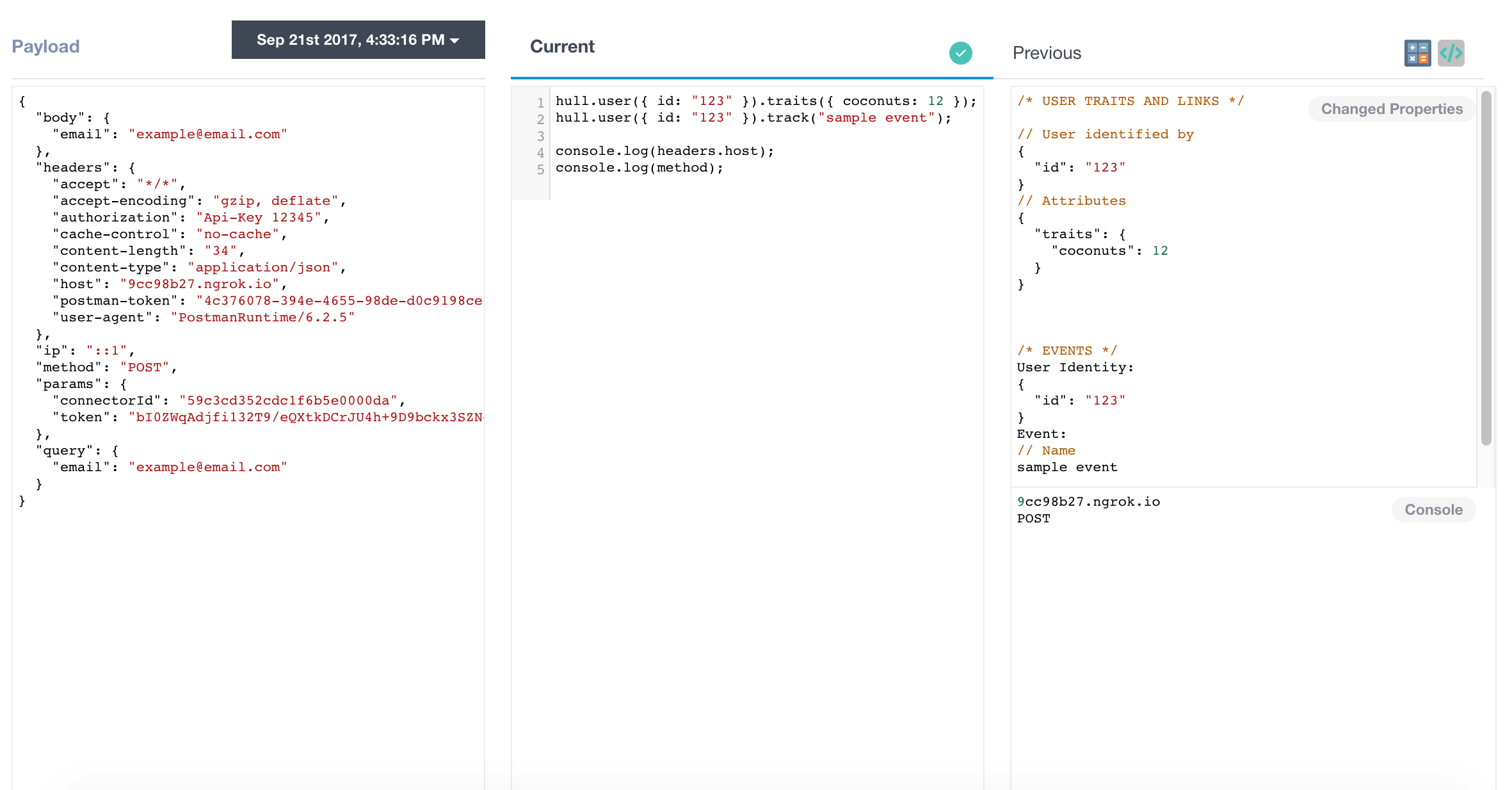
Est-ce que ça a marché ? Pour le savoir, il suffit d'aller sur l'interface des logs de Hull :

L'interface marche relativement bien. C'est du Kibana derrière et il est simple de filtrer par champ, tranche de date etc…
Le seul petit piège, c'est que Hull gère ça sans doute en interne sous forme de queue de message. De votre côté vous avez simplement reçu un code d'acquittement 204 (reçu mais sera traité plus tard).
Et cette attente peut aller jusque 5/10 minutes. Donc le feedback est assez long entre votre envoi et le résultat.
Ce n'est clairement pas un souci dans le cas nominal parce que le choix est totalement logique d'une part, vu le volume Hull a pris une bonne décision sans doute, et d'autre part vous n'êtes pas à la minute pour un update dans la majorité du temps.
Mais j'avoue qu'en développement c'est un peu frustrant, notamment car l'appel de l'API ne fait aucun contrôle de surface donc pendant la phase d'intégration il arrive souvent de devoir attendre plusieurs minutes juste pour voir que votre format comporte une erreur (dans le token JWT la très grande majorité du temps).
J'avoue qu'en dev j'aurais aimé un mode dégradé avec contrôle immédiat, mode à interdire en production bien sûr.
Utilisation d'un Incoming Webhook
La seconde solution proposée repose sur un Webhook côté Hull que l'on retrouve documenté ici.
Sur le principe j'ai rapidement choisi de ne pas utiliser cette solution.
L'idée étant d'envoyer n'importe quel objet JSON et d'utiliser ensuite un éditeur de texte depuis l'interface d'admin de Hull pour traiter ce JSON et appeler directement l'API de Hull depuis cet éditeur en ligne.
J'avoue qu'avoir du code non versionné de mon côté, non testé et à synchroniser en même temps qu'un changement d'API, était plutôt rédhibitoire. Même si je comprends l'idée, cela permet à des utilisateurs "non tech" de votre équipe marketing de pouvoir hacker directement de leur côté. En pratique, je ne sais pas si c'est vraiment un cas d'usage fréquent d'avoir des personnes de l'équipe marketing qui font du javascript sur ce type d'interface.
Utilisation d'un connecteur d'import
Cette solution est pour moi la plus séduisante sur le papier et je pense que nous l'utiliserons dans l'avenir. Il s'agit d'un connecteur direct sur une source de données.
L'idée étant de créer une vue sur votre source de données et dès qu'elle change, les modifications sont reportées chez Hull. La seule chose à maintenir est donc une vue SQL par exemple sur votre base analytique.
Malheureusement nous ne l'avons pas testé car pour l'instant ce connecteur n'accepte pas encore les Datasources BigQuery : https://www.hull.io/docs/connectors/sql-importer/
Un défaut majeur
Sur le papier Hull est effectivement très pratique plutôt que de devoir maintenir des intégrations sur tous vos outils tierces, Intercom, Mailchimp, Salesforce, Customer.io pour ne citer que ceux la par exemple.
En effet Hull ayant des connecteurs pour ces outils, ce n'est plus à l'application de gérer ces données vers ces outils.
En pratique c'est globalement vrai, sauf… pour la suppression.
Déjà la suppression de données dans Hull est peu triviale dirons-nous.
Un enregistrement dans Hull est identifié par un ID qui ne correspond pas à votre ID logique. En effet vous pouvez préciser un ID logique (external_id) correspondant aux ID utilisé dans votre application mais Hull a ses propres ID. Or l'API de DELETE ne fonctionne qu'à partir des ID Hull. Dommage de ne pas avoir proposé de DELETE qui fasse un lookup avec un external_id.
D'ailleurs le DELETE n'est pas vraiment documenté pour les users : https://www.hull.io/docs/reference/http\_api/
Une fois qu'on a cependant compris que l'on peut supprimer un user par son vrai ID, il faut le trouver.
Il faut donc
- utiliser l'API de search par son external_id. Vous noterez que cela ressemble furieusement à une requête elasticsearch
- lire l'ID interne dans le résultat
- appeler l'API de DELETE qui n'est pas documenté sur cet ID
Je ne cache pas, ça pique un peu.
Mais surtout, le DELETE n'est pas propagé vers les autres outils. Et c'est la le plus gros souci.
Une solution un peu "bof" c'est de ne pas faire un DELETE mais de faire un UPDATE et de mettre à null tous les champs, ce qui rend la donnée totalement inutile.
En pratique, ca ne semble pas bien marcher non plus. Chaque outil ne supporte pas forcément de mettre à null l'ensemble des champs. De plus, Hull fonctionne aussi dans l'autre sens avec ces connecteurs.
Autrement dit le connecteur vers Intercom, il met aussi à jour la donnée vers Hull. Donc on peut nullifier dans Hull puis récupérer la donnée depuis intercom. Du coup on ne s'en sort jamais.
Pour l'instant nous avons donc du créer des intégrations avec les autres outils (intercom etc…) pour supprimer nous même la donnée. Ce qui est quand même un gros défaut pour la solution et je ne suis pas certain de la fiabilité. Il est bien évident que nous travaillons toujours là dessus.
L'export de données
C'est un autre atout de Hull. Hull est aussi rempli d'informations utiles car il permet par exemple de savoir qu'il y a eu des contacts sur intercom, il peut indiquer les emails envoyés par customer.io ou avoir été enrichi par Clearbit etc…
Bref, de nombreuses choses que l'on veut récupérer ensuite chez soi.
Pour l'export, nous avons donc mis en place un Outgoing Webhook vers notre plateforme Data.
Une fois mis en place, ce webhook permet de faire du BigQuery streaming et d'insérer la data directement depuis un code python deployé en Serverless dans Google Cloud Functions.
Je ne détaille pas trop car cette architecture de plateforme data serait sans doute intéressante à décrire dans un autre billet.
A savoir cependant sur ce webhook, plusieurs choses ne sont pas documentées :
- La doc ne précise pas comment sécuriser le webhook. Le support indique cependant qu'il faut paramétrer le webhook en https avec un paramètre GET secret que l'on lit dans le code de réception
- la doc ne précise pas si Hull gère bien les cas où notre API échoue (et oui, nous aussi on peut échouer). A priori le support nous indique qu'il y a bien des retry mais nous n'avons aucune info, aucune stats, aucun monitoring donc cela reste un peu mystérieux.
C'est tout pour ce billet. Au delà de l'outil, j'espère qu'il a pu être intéressant sur les approches employés ou pour avoir un aperçu de notre plateforme Data.
A bientôt


